网络安全领域一些前沿进展
参加2026年第三届网络安全青训营的见闻
大语言模型安全
来自腾讯玄武实验室——于旸
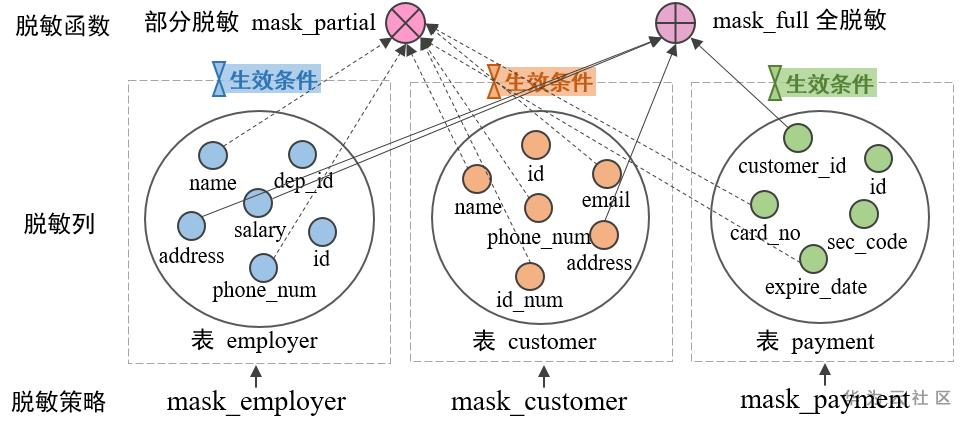
端到端的同态脱敏
大模型已经被广泛应用在各类场景,帮助人们进行报告摘要、文本翻译、数据分析、业务风控等各项工作,极大地提升了工作效率,但同时公众对于大模型带来的数据泄露的隐忧也从未停止。由于在使用大模型时用户不可避免地会出现输入敏感信息,如何保证输入的敏感信息不被泄露或窃取成为了一个重要的研究课题。这就产生了“脱敏”这一研究项目,具体来说,脱敏期望用户输入的内容中,敏感信息被等效替代,使得大模型能基于被“脱敏”的文本进行处理分析。
传统技术,例如微软的Presidio脱敏范式,通常是用通用的符号、掩码替换敏感信息。例如,LLM已知
国际商业机器公司(International Business Machines Corporation)是一家国际化科技公司,通常被简称为IBM。IBM以其在计算机硬件、软件和服务方面的创新而闻名。
当用户提问:
International Business Machines Corporation以什么闻名?
用户期待的LLM回答为:
以其在计算机硬件、软件和服务方面的创新而闻名。
假设在LLM已知的内容中,IBM及其全称是敏感信息,在微软的Presidio脱敏策略下,LLM的已知信息被替换为:
XXX(XXX)是一家国际化科技公司,通常被简称为XXX。XXX以其在计算机硬件、软件和服务方面的创新而闻名。
这么做确实起到了脱敏的作用,但是原本的语义信息和指代关系就丢了。AI读到“XXX”时,无法理解这到底是一个具体的实体,还是一个变量,甚至可能导致句子语法不通顺。这会极大地限制LLM生成内容。
而同态脱敏被期待做到保留原有的语义关系和指代关系。在腾讯玄武实验室介绍的HaS同态脱敏技术中,LLM的已知内容被期待为:
跨国科技公司(Global Technology Corporation)是一家国际化科技公司,通常被简称为GTC。GTC以其在计算机硬件、软件和服务方面的创新而闻名。
显然地,同态脱敏在尽可能地用同义内容掩盖原有的敏感信息。
Prompt Cache 侧信道攻击
我们都知道,大语言模型的推理成本极高,尤其是当处理长文本时,计算资源的消耗非常巨大。为了提升用户体验并降低成本,现在的云端推理框架普遍引入了一种名为提示词缓存(Prompt Cache)的机制。其原理简单来说,就是当服务器发现当前用户输入的提示词前缀(Prefix)与之前处理过的请求高度相似时,系统会直接复用之前已经计算好的中间状态(即 KV Cache),而无需从头重新计算。
这种机制在正常情况下是双赢的:用户获得了更快的响应速度,服务商节省了算力。然而,正是这种“为了变快”的机制,为攻击者留下了一个隐蔽的侧信道。所谓的侧信道攻击,在这里利用的介质正是“响应时间”。
研究发现,当一个请求命中了缓存时,服务器的响应速度会极快,通俗来讲可以理解为首字生成时间大幅缩短;而如果没有命中缓存,服务器则需要按部就班地计算,响应速度自然较慢。这种显著的时间差异,可以被直接用作判断这段内容有无被缓存。
假设受害者刚刚利用云端大模型起草了一份包含个人隐私的租房合同,其中涉及了他的身份证号。这段包含敏感信息的上下文被留存在了服务器的公共缓存池中。攻击者虽然无法直接读取缓存,但其可以利用上述的时间差异进行一种类似SQL布尔盲注一样的提示词盲注。攻击者会精心构造一段提示词,前半部分是通用的合同模板,用来对齐上下文,后半部分则是其试图猜测的敏感信息。
显然地,我们没法直接用手构造这样的盲注测试,SQL布尔盲注尚且可以枚举,而人类与大语言模型的对话信息量巨大,根本无法通过暴力枚举进行碰撞从而泄露缓存。基于此,同样也为了提高攻击的效率和隐蔽性,讲座中提到了一种更为精妙的辅助手段——本地孪生语言预测器。
本地孪生语言预测,从理论上来说,是攻击者在本地部署的一个轻量级的小模型。这个本地模型会根据已有的上下文,分析下一个字最可能是什么。比如,当前文是“北京市海淀区”时,本地模型会预测下一个字大概率是“中关村”的“中”或“五道口”的“五”,而不太可能是毫无关联的字。攻击者只需将这些高概率的候选Token发送给云端服务器进行测试,一旦命中缓存,就通过了验证。
当然实际实现起来,这种攻击并没有说起来这么简单,但是展示一个LLM快速发展的当下我们需要注意的问题。
大模型智能体驱动的软件安全研究
来自香港科技大学——王帅
王帅老师提出了全栈式解决方案:
应用层(application layer): 共性与特性
- 针对各种细分场景的安全任务做优化
- 预期通过复用安全规范、编码规范、核心知识和基础技能, 支撑迁移复用安全智能体
算法层(algorithm layer): 成本与效益
- 对开源模型赋能深度思考能力来提升效果、降低幻觉、假阳性等
- 构建业务领域智能体,通过工具、迭代等在可控Token成本内有效完成任务
数据层(data layer): 深度与广度
- 高质量的通用训练数据合成和筛选在广度上支撑模型在业务领域的专业度和准确率
- 高质量的专有数据合成在深度上支撑领域应用、长链数据在支撑深度思考和推理
数据层
在王帅教授关于“大模型智能体驱动的软件安全研究”的报告体系中,数据层(Data Layer)被视为支撑整个大模型安全应用大厦的基石。报告开篇即指出了当前安全领域在数据层面面临的核心挑战:即如何在“广度”(通用场景)和“深度”(专有场景)上同时支撑代码相关的应用。通用场景往往面临数据量虽大但质量参差不齐的问题,而专有场景则面临高质量、长上下文、逻辑严密的数据极其匮乏的困境。为了打破这一瓶颈,报告重点介绍了两种极具创新性的数据合成与增强技术,分别利用了编译器技术的严谨性和API的抽象能力,实现了低成本、高效率的数据构建。
基于编译器中间表示的语义一致性数据增强
针对高质量代码训练数据稀缺,尤其是缺乏语义一致但结构多样的样本这一痛点,王帅教授团队引入了编译器技术来辅助AI训练。在论文中,研究团队提出了一种巧妙的思路:利用编译器在将源代码转化为中间表示过程中的优化机制来进行数据增强。
我们知道,一段源代码在经过编译器——尤其是LLVM——王帅老师专门举例——处理时,可以通过应用不同的优化序列,生成多种不同形态的中间代码,但这些代码所执行的逻辑功能/语义是完全一致的。这项研究正是利用了这一特性,通过组合不同的编译器优化选项,自动化地生成海量语义等价但表现形式各异的代码训练数据。这种方法从根本上解决了传统代码生成中语义漂移或不一致的问题。
这项技术的落地效果十分显著。在2022年,该技术与腾讯科恩安全实验室合作,助力腾讯的CodeCMR模型在代码理解与表征能力上实现了质的飞跃,其性能较大幅度超越了当时业界主流的CodeBert系列模型。这不仅验证了“利用传统程序分析技术反哺AI模型”的可行性,更直接赋能了科恩实验室数据驱动的软件供应链管理方案,提升了其在实际工业场景中的代码分析能力。
API牵引的低成本微调数据筛选与合成
API-guided Dataset Synthesis to Finetune Large Code Models (OOPSLA 2025)
除了基础训练数据的增强,如何针对特定领域进行高效的模型微调是数据层的另一大挑战。现有的开源微调数据集往往存在“通用数据过剩,专有数据不足”的结构性失衡。为了解决这一问题,报告介绍了另一项重要成果,即上述论文。
该研究提出了一种名为DATASCOPE的筛选与合成框架,其核心思想是将API视为编程语言的天然抽象锚点。API不仅浓缩了代码的功能意图,还可以作为一项“牵引指标”,帮助大模型在茫茫数据海中精准定位有价值的样本。在数据合成方面,该框架设计了一套领域专用语言(DSL)来为生成的程序提供严格的代码结构保证,通过自动化构建API图谱来限制和规范代码的功能逻辑,从而生成兼顾控制流完整性与功能正确性的高质量合成数据。
更值得一提的是该框架引入了“由弱到强”的渐进式难度控制机制,优先考虑训练数据的难度分布,平衡模型的生成能力与成本。这项技术的经济效益极高:实验数据显示,使用DATASCOPE筛选出的数据进行训练,仅需原本5%的数据量就能达到同等的模型微调效果。而在数据集构建成本上,自动化合成框架将原本需要消耗334个人力时(参考OpenAssistant数据集构建标准)的4000条高质量数据构建过程,压缩到了仅需花费3美元的API调用成本。这极大地降低了垂直领域安全大模型构建的门槛,使得针对专有场景的深度定制成为可能。
算法层
Testing and Understanding Erroneous Planning in LLM Agents through Synthesized User Inputs
在当前的软件安全研究中,算法层面临着成本与效益、深度与广度的双重博弈。虽然商业闭源大模型(如OpenAI的o1系列)在逻辑推理任务上表现出色,但出于安全、用户体验及商业竞争力的考量,这些模型通常不会公开其内部的思考过程和方法,导致研究者无法窥探其“黑盒”内部的推理逻辑。更为关键的是,开源大模型如LLaMA、Falcon等普遍缺乏主动的深度思考能力,在面对复杂的安全任务时容易产生幻觉或浅尝辄止。因此,如何在开源模型中引入并增强“深度思考”能力,使其在可控的计算成本内具备高级推理和知识整合能力,成为了算法层研究的核心目标。
为了填补这一鸿沟,王帅教授团队在算法层提出了一套以“推理能力提升”和“知识整合”为双引擎的增强方案。在推理能力方面,研究不再局限于简单的问答交互,而是致力于优化“思维链”技术。通过将复杂的安全问题——尤其是CTF——拆解为更小的子问题,引导大语言模型进行多步骤推理,并强制模型展示其推理过程。这种方法不仅能保持逻辑的连贯性,还能通过跟踪中间步骤来减少错误。更进一步地,研究引入了“迭代式完善”与“自洽自我批判”机制,即让模型在生成答案后进行自我反思,或者通过角色扮演的方式对推理结果进行验证,从而实现模型内部的“优胜劣汰”。针对模型在规划过程中可能出现的错误,王帅团队进行了深入的机理研究,在论文中,通过合成用户输入来测试和理解LLM智能体在规划阶段的错误模式,旨在解决复杂问题中“过早放弃”或简单问题中“过度思考”的困境。
在知识整合方面,单纯的推理能力往往受限于模型训练数据的时效性和准确性,导致“幻觉”现象频发。为此,算法层采用了检索增强生成(RAG)与外部工具集成相结合的策略。一方面,通过将大语言模型与结构化的网络安全知识图谱(如Wikidata及专有的安全图谱)相集成,使模型在推理过程中能够实时检索并融合多源知识,确保推理基于准确的事实而非概率性的猜测。另一方面,算法赋予了模型调用外部复杂工具的能力,例如符号执行引擎和约束求解器。这意味着大模型不再仅仅是一个文本生成器,而是成为了一个能够生成并执行代码片段、进行复杂计算或模拟的智能中枢。
此外,算法层的构建还需要兼顾安全性与防御机制。在探索如何防止大模型被恶意利用或产生有害输出时,王帅教授团队提出了基于“上下文感知”的防御策略。在论文中,研究团队展示了如何利用大模型自身的理解能力来防御越狱攻击,即让模型在执行指令前先结合上下文判断用户的真实意图,从而在实用性与安全性之间取得平衡。
Function Calling as a Flexible LLM Defense Add-On: Capability and Application
同时,针对模型行为的规范化,团队还探索了将防御逻辑“代码化”的路径,在投稿论文中,提出了利用“函数调用”作为一种灵活的防御插件,将模糊的文本审查转化为精确的函数参数检查,进一步提升了算法层在应对复杂安全场景时的鲁棒性和可解释性。
应用层
当前软件安全领域正面临着日益复杂的挑战,传统的静态分析与人工审计在面对海量代码与复杂逻辑时显得力不从心。为了突破这一瓶颈,研究人员提出了一套以大语言模型(LLM)为核心的深度思考架构,旨在利用增强的开源模型支撑关键的软件与安全任务。这套体系并非简单的接口调用,而是通过构建“应用层、算法层、数据层”三位一体的生态,实现了从自动化攻击到防御的全面赋能。其核心在于利用LLM的语义理解与逻辑推理能力,结合外部工具的反馈机制,在模糊测试、逆向工程、漏洞挖掘及修复等多个垂直领域取得了超越传统方法的突破。
进攻性安全任务
Measuring and Augmenting Large Language Models for Solving Offensive Security Challenges. (CCS 2025)
在进攻性安全任务中,CTF是检验AI能力的重要试金石。研究团队提出的CTFAGENT系统展示了这一领域的最新进展。该系统通过爬取权威CTF归档网站构建专用知识库,并利用双LLM架构分别进行知识提取与幻觉过滤,确保了核心知识的准确性。在解题过程中,CTFAGENT不再是单步输出,而是集成了一个包含反编译工具、调试器及密码学工具的完整环境。模型能够在多轮推理中根据环境反馈——无论是代码报错还是工具执行结果——不断修正自身的攻击脚本,直至发现Flag。这种基于反馈的迭代机制使得该系统在picoCTF 2024国际赛事中获得了排名前23.6%的优异成绩 。
漏洞挖掘误报率高
针对软件漏洞挖掘中静态分析工具如CodeQL误报率极高这一痛点,研究通过引入“警报验证器”与“规则优化器”重塑了工作流。传统的静态分析往往会输出海量警报,人工排查耗时耗力。新的方案利用GPT-4模拟开发人员的思维链,结合控制流图与数据流图对警报进行深度研判,通过解释代码功能来识别误报。更进一步地,系统能够总结误报特征,自动生成定制化的CodeQL查询规则,从而在源头批量屏蔽同类误报。实验表明,这种方法在CWE数据集上降低了超过60%的误报率,且未漏报真实漏洞,极大提升了审计效率 。
Fuzzing
在模糊测试领域,大模型的引入解决了传统方法难以生成高质量种子输入的难题。针对深度学习库,DFUZZ系统通过提取API文档与源码中的边界情况,利用LLM推理出特定的张量维度或极值输入,显著提升了对库函数的覆盖率 。
而对于图像、音频等非文本格式的模糊测试,G2FUZZ系统提出了一个精妙的思路:既然LLM难以直接生成二进制文件,不如让它生成“生成器”代码。通过分析文件格式特征,LLM编写出能产生特定格式文件的Python脚本,再通过变异这些生成器本身来覆盖更多测试路径,这种“生成生成器”的策略成功发表于USENIX Security 2025 。
静态逆向
在二进制代码的逆向与迁移方面,研究同样强调了“闭环反馈”的重要性。针对反编译代码可读性差且难以重编译的问题,DecLLM系统利用编译器和模糊测试工具的报错信息,引导大模型反复修正伪代码,直至其功能完全正确 。
No More Translation at Runtime: LLM-Empowered Static Binary Translation. (EuroSys 2026)
而在涉及国产化替代的二进制翻译场景中,LLMSBT系统提出了一种静态翻译流水线,利用LLM将x86汇编翻译为ARM汇编。为了保证正确性,系统要求模型先解释指令含义,再进行翻译,并经由静态分析验证。这种方法避免了运行时翻译的开销,在性能上实现了数量级的提升。
基于大语言模型的自主渗透测试框架:SecLine 与 SecFlow
来自北京大学——周昌令
众所周知,尽管国际上诸如 DARPA AIxCC 挑战赛和 XBOW 等自主渗透产品已经取得了里程碑式的突破,甚至展现出了自主发现 0day 漏洞的能力,但在实际的复杂场景应用中,主流的 ReAct 智能体框架依然面临着严峻的考验。目前的智能体难以完成长时间的持续运行,面对逻辑复杂的渗透测试任务时,往往表现出扩展能力差、自动利用浅等问题。这背后实际上存在一个核心矛盾,即漏洞信息多为半结构化的自然语言描述,关键信息(如前置条件、后果、可关联性)缺失,这与渗透测试过程中所需的确定性决策之间存在着难以调和的冲突。如何在复杂场景中进行有效的任务决策,以及如何利用获取的长链条信息而不遗忘,是当前研究亟需解决的难点。
为了解决上述“环境感知”层面的漏洞信息缺失问题,讲座中介绍了一种名为 Crimson 的关键技术,旨在赋能大语言模型在网络安全领域的战略推理能力。面对 CVE 漏洞描述模糊、缺乏与 ATT&CK 等技战术框架自动关联的现状,Crimson 引入了检索增强(Retrieval-aware)训练和合成数据生成技术。其本质是通过构建合成的漏洞伪影和对齐结构,训练模型从非结构化的自然语言中提取出包含前置条件、可替代性及产生后果在内的关键信息,并将其映射到结构化的 ATT&CK 技术中。这种战略推理能力使得智能体能够像人类专家一样,基于多源信息发现并分析漏洞组合链,从而极大地提升了自动化渗透的深度与准确性。
在解决了信息感知问题后,核心的挑战在于如何赋予智能体像人类专家一样的思考和规划能力,即“任务推理”。这里提出了一种从“命令与控制”到“任务式指挥”的交互新范式。传统的渗透测试往往要求人类角色提供详细步骤,AI 仅负责具体执行,这不仅导致人类认知负荷高,且难以应对动态变化。而新一代的 SecLine 框架则倡导“目标式对话”,人类只需定义目标和意图(例如“找出暴露的 Jenkins 并评估风险”),由 AI 角色自主规划执行路径、调整决策并优化方案。SecLine 作为认知智能体框架,通过上下文管理层、模型接入层和工具调用层的分层设计,实现了对渗透测试任务的认知驱动,将关注点从“如何做”转变为“做什么和为什么做”,显著提升了人机协同的效率。
进一步地,为了让智能体能够灵活地使用各种渗透工具,SecExtend 框架应运而生,它通过“工具学习”实现了对渗透工具的标准化封装。SecExtend 采用了模型上下文协议(MCP),将复杂的渗透工具封装为具有明确输入输出的“原子化工具”。这一设计的精妙之处在于它解耦了智能体的决策逻辑与具体工具的执行细节。智能体只需根据任务需求调用和组合这些原子工具,而无需关心工具底层的运行机制或复杂的参数适配。这种动态注册和发现机制,不仅支持新工具的快速扩展,还适应了渗透工具长时间运行的特性,极大地降低了系统集成的复杂度,提高了整体系统的灵活性。
最终,上述关键技术被整合进了下一代智能渗透测试框架 SecFlow 中。作为 SecLine 的演进版本,SecFlow 致力于构建一个全自动化的渗透引擎。在演示的场景中,我们可以看到一个完整的长链条多阶段渗透路径:从指纹识别开始,经过 Payload 变形绕过防护、植入 VShell、获取信息,再到内网横向移动,最终自动生成渗透报告。整个过程无需人工干预,系统甚至具备失败自动重试的能力,真正实现了从单点突破到全链路自动化渗透的跨越。这标志着自主渗透测试正从单纯的脚本执行,迈向具备高认知、强推理和灵活工具调度能力的智能化新阶段。