离线赛时代码审计的一种解决方案
使用Ollama下的Qwen3.5-9b与VSCode continue插件搭配
安装Ollama
Ollama 是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计,允许用户在本地快速加载、管理和运行各种大型语言模型,如 Llama、Mistral、Qwen、Gemma 等,而无需依赖云服务或复杂的基础设施。它的核心目标是简化模型部署和推理流程,使开发者和研究人员能够高效进行自然语言处理任务,包括文本生成、翻译、问答、代码编写和情感分析等。
在PowerShell输入:
1
irm https://ollama.com/install.ps1 | iex
等待自动化安装结束即可。安装结束后输入:
1
ollama help
看到有信息输出即可。
安装Qwen3.5-9b
Qwen 3.5 is a family of open-source multimodal models that delivers exceptional utility and performance.
截至2026年3月17日,Ollama上最新最热门的llm就是Qwen,我的机器配置为RTX4060 laptop(8Gb显存),使用9b模型有些许吃力,但是9b相较于4b来说聪明不少,在离线环境下宁缺毋滥,我们依然使用9b。输入:
1
ollama run qwen3.5:9b
即可安装qwen3.5-9b模型,下载安装好之后可以直接使用。
但是一个很常见的问题是,由于硬件限制和Ollama默认参数的影响,将整个代码喂给本地AI会高发循环思考——即不断地输出重复的思维内容而不停止思考,为了解决这个问题,我们要对模型进行参数调整。
在任意目录下新建一个文件,文件名任意,这里命名为Modelfile,没有扩展名,在里面输入:
1
2
3
4
5
6
7
8
9
FROM qwen3.5:9b
PARAMETER num_gpu 99
PARAMETER num_ctx 6144
PARAMETER repeat_penalty 1.2
PARAMETER temperature 0.6
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|endoftext|>"
这些配置使得模型被要求必须使用独立显卡、预设上下文长度为6144Kb、重复惩罚系数为1.2、温度为0.6,经过实际测试,这个参数可以极大地降低循环思考的概率,大部分情况下,AI面对较长代码和较短的prompt有良好的输出效果。
保存文件,在该目录下执行:
1
ollama create qwen3.5-9b-fix .\Modelfile
即可生成一个新的模型。生成新的模型不会在本地创建一个模型副本,所以不必担忧空间问题。
之后通过:
1
ollama run qwen3.5-9b-fix
即可正常访问。
安装并配置Continue
Continue插件是VSCode上对Ollama支持较好的Vibe Coding插件,能够更好帮助我们审计并修改代码。
在插件市场搜索并安装即可。
进入界面后,先本地随意跑起一个ollama模型:
1
ollama run qwen3.5:9b
然后点击Local Conig -> Reload即可看到有本地模型。直接开始使用即可
在2025年CISCN半决赛AWDP审计上,效果良好:
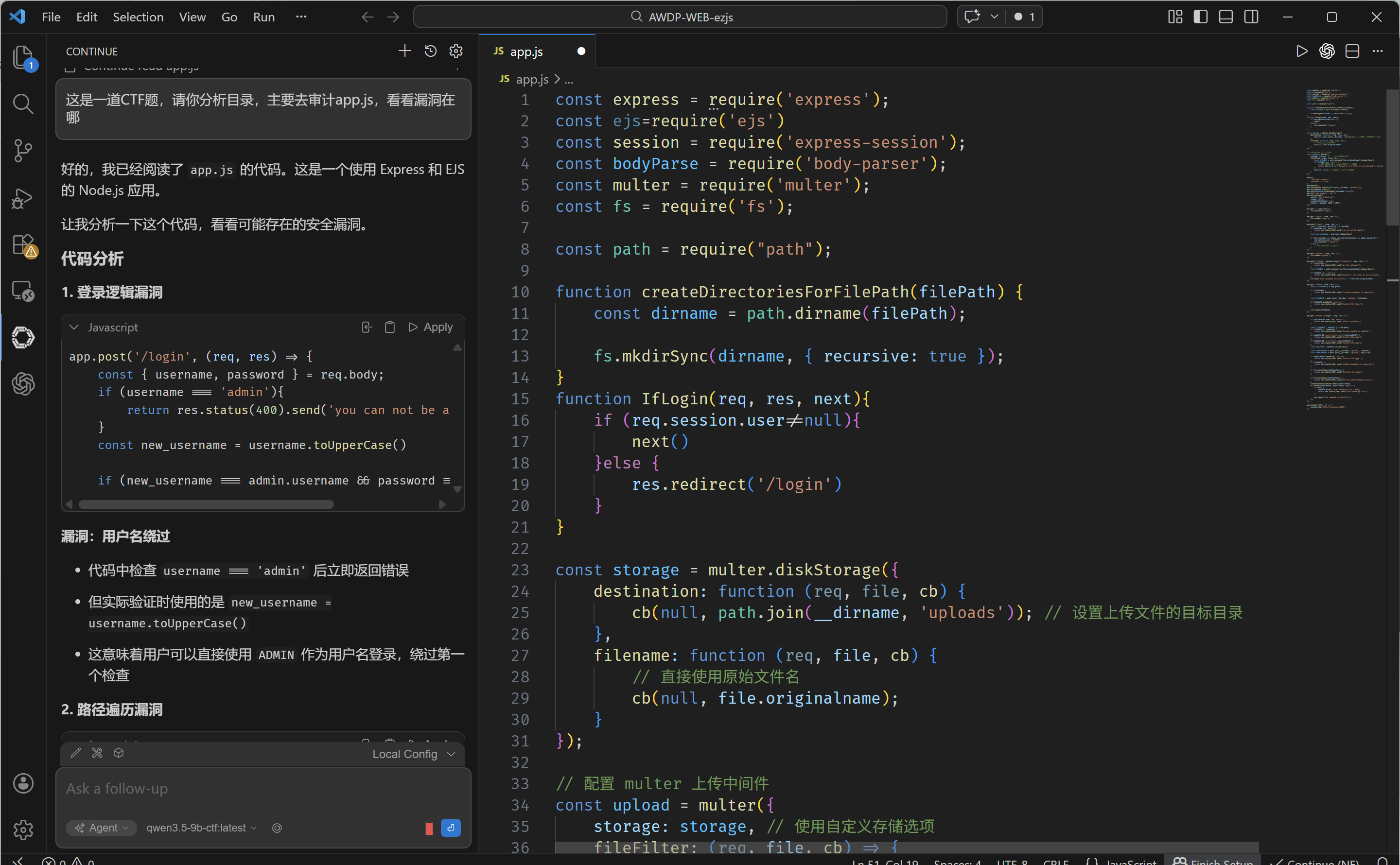
当然,本地AI无法一把梭哈CTF题目,但是能很大程度上解决离线情况下许多问题,比如脚本不太会写、漏洞不太会修、参数突然忘了、语法不太对劲等问题。
拥抱AI就是拥抱未来。